
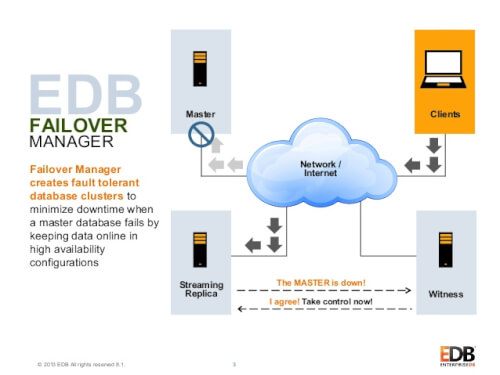
EnterpriseDB, entre las herramientas que proporciona a los clientes, cuenta con EDB Postgres Failover Manager (EFM) para cubrir la alta disponibilidad del servicio de base de datos. EFM, monitoriza el estado de los clusters de base de datos y actúa en caso de error rápidamente. Cuando se produce un error, puede promover un nodo esclavo a maestro, manteniendo la continuidad y rendimiento del servicio, así como dando protección ante posibles pérdidas de información.
Entre los últimos cambios integrados en EFM versión 3 están, por un lado, múltiples hooks que nos permiten complementar las funcionalidades de EFM con otras, y que ofrecen herramientas como pgpool.
Por ejemplo, un caso muy común en nuestros clientes, es la necesidad de ofrecer alta disponibilidad y balanceo de carga en el servicio de base de datos. Pero sin poder usar una IP virtual VIP, ¿entonces, qué opción tenemos? Utilizar la capacidad de balanceo de carga que nos ofrece pgpool y la alta disponibilidad la cubrimos con EFM. ¿Y cómo hablan EFMy pgPool? Mediante los siguientes propiedades de configuración:
script.load.balancer.attach= script.load.balancer.detach=
Dentro del fichero de configuración de EFM, efm.properties, podremos definir dichas propiedades. Con estos hooks, será más sencillo soportar casos como el switchover, fallo en algún esclavo, o fallo del maestro que no termine con una correcta promoción.
Para conocer un poco más de cada una de estas propiedades, vamos a detallar los casos de error que contemplan cada una. Para el hook de detach:
- Después del fallo de una base de datos. El script será invocado por el agente local a la base de datos que ha fallado.
- Después del fallo en un nodo de base de datos. En este caso, otro agente será el responsable de llamar al script, pasándole la ip/hostname del nodo con error como parámetro. Como es otro agente el que llama al script de detach, es importante que todos los nodos que pertenecen al cluster EFM tengan una copia de los scripts.
- Cuando el agente del maestro detecta que éste se ha quedado aislado de la mayoría de nodos del cluster. En este caso, el agente del maestro, no puede contactar con el balanceador de carga, pero de todas formas lo intentará. Para el resto de miembros del cluster, éste será un caso de fallo en un nodo de base de datos y se actuará tal como se explicaba en el caso anterior.
En resumen, cualquier condición que pudiera causar que el agente del maestro o esclavos entre en modo ‘IDLE’, o si el resto de miembros del cluster detecta que un nodo desaparece, entonces el script de ‘detach’ será llamado.
Los casos que serán contemplados por el hook de ‘attach’ son:
- Una promoción de un nodo que se convierta en maestro. Este es el caso en el que cualquier esclavo se convierte en maestro, ya sea por un failover, una promoción manual o la ejecución de un switchover.
- Un agente en estado ‘IDLE’ reanuda la monitorización de la base de datos maestra o esclava, después de un fallo. Esto ocurre cuando un fallo en la base de datos ha sido corregido o se ha reiniciado, y el agente vuelve a monitorizar el estado, después de ejecutarse el comando efm resume o ha pasado el periodo definido en la propiedad auto.resume.period.
- Un agente en estado ‘IDLE’ vuelve a monitorizar después del arranque. Un ejemplo de este caso es cuando se enciende un nodo, efm arranca, la base de datos arranca y al agente de efm se le indica que vuelva a monitorizar el cluster. La base de datos aún no está disponible para el balanceador porque no estaba funcionando previamente.
- Un agente ‘IDLE’ vuelve a monitorizar la base de datos maestra original que ha sido reiniciada como esclava después de un switchover.
Resumiendo, cualquier condición que cause que un agente pase a estado ‘IDLE’ o promocione para ser convertido en maestro o esclavo, llamará al script de ‘attach’.
Para ver un caso real, vamos a partir de un nodo de base de datos que tenga asociada la ip 10.0.100.10 y con la siguiente configuración:
script.load.balancer.attach=/somepath/attach_script.sh %h script.load.balancer.detach=/somepath/detach_script.sh %h
Si la base de datos en el nodo se para, lo siguiente sería ejecutado por el usuario bajo el que funciona Failover Manager ( generalmente el usuario ‘efm’), pasándole la dirección IP al nodo de base de datos que debiera ser eliminado de la configuración del balanceador:
/somepath/detach_script.sh 10.0.100.10
También podemos definir los hooks de attach y detach con un mismo script, incluyendo un parámetro adicional donde se especifica si la acción es de attachment o detachment del nodo:
script.load.balancer.attach=/somepath/lb_script.sh attach %h script.load.balancer.detach=/somepath/lb_script.sh detach %h
En este caso, la instrucción que el agente de EFM ejecutaría sería:
/somepath/lb_script.sh detach 10.0.100.10
Si un nodo falla, entonces otro nodo llamaría a su script de detach local, tal como se muestra arriba, pasándole la dirección IP del nodo que falló. Así es porque es importante que todo nodo de EFM tenga una copia o acceso a los scripts de attach/detach si utilizamos los nuevos hooks para integrar EFM con balanceadores.
Puedes encontrar el contenido original aquí.
